
Beyond OpenAI- Harnessing Open Source Models to Create Your Personalized AI Companion 💻
Learn how to create your own AI companion using open-source models and the LangChain framework. I



Introduction
Imagine having a personal assistant who can engage in interactive conversations, provide insightful information, and help you navigate your vast knowledge base. A companion that understands your queries and responds with relevant and tailored answers. This is precisely what I set out to achieve with my latest project.
As someone with a profound collection of knowledge on deep learning, meticulously organized in my Obsidian Vault, I wanted to create a personal assistant that could serve as an intelligent interface to interact with this knowledge base. I envisioned a seamless experience where I could engage in natural language conversations and effortlessly retrieve valuable insights from my extensive repository of information.
In my previous blog, I explored the exciting possibility of creating your very own YouTube GPT using LangChain and OpenAI. We created a system that enabled us to engage with video content in an entirely new way. OpenAI, while undeniably brilliant, is not as open as its name suggests. It comes at a cost, a paywall that separates the curious from the unlimited possibilities that lie within. However, this time, we're taking a different path—one that leads us to the world of open source models, where freedom and accessibility reign supreme. In this blog, we will dive into the realm of open source AI models that are freely available for use, breaking away from the limitations of proprietary systems like OpenAI. Together, we will unlock the true potential of AI by harnessing the capabilities of the MPT-7B-Instruct Model, developed by Mosaic ML and served by GPT4All, alongside LangChain.
MPT-7B is an amazing open source language model created by the talented folks at Mosaic ML. This model is truly remarkable with its ability to understand and generate text that feels just like human conversation. What sets MPT-7B apart is its special fine-tuning to provide instructive responses, making it perfect for building your own personalized AI companion.
LangChain is a powerful tool that facilitates the creation of AI models tailored to specific domains or languages. It allows users to train language models on custom datasets, making it ideal for developing specialized AI applications. With LangChain, you can fine-tune models to suit your unique needs, enabling more accurate and context-aware responses. By leveraging the capabilities of LangChain, you can enhance the performance of your AI system and create a more personalized and effective conversational experience.
Now let us get coding...... As always, a link to the Git Repo will be available at the bottom of this post.
Start a new python project and initiate a new virtual environment. Create a python file name private_gpt.py
Install Dependencies
In order to get started with building your personalized AI companion, there are a few dependencies that need to be installed. The code block above shows the necessary packages that need to be installed, which can be done by running the following command:
pip install -qU langchain tiktoken gpt4all streamlit-chat einops transformers accelerate chromadb
Import Dependencies
To kick start the development of our personalized AI assistant, we begin by importing the necessary dependencies. These libraries and modules will provide the foundation for our assistant's functionality and enable us to interact with various components seamlessly.
from langchain import ConversationChain,PromptTemplate
import torch
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import TextLoader, DirectoryLoader
from langchain.llms import GPT4All
import os
from langchain.memory import VectorStoreRetrieverMemory
import streamlit as st
from streamlit_chat import message
Create Data Loader
loader = DirectoryLoader('D:/OneDrive/Documents/Obsidian/Projects/myVault/', glob="**/*.md",recursive=True, show_progress=True, use_multithreading=True, loader_cls=TextLoader)
docs = loader.load()
len(docs)
Now that we have imported the necessary dependencies, let's move on to creating a data loader. This loader will enable us to load and process text documents from our knowledge base, which will serve as a valuable source of information for our personalized AI assistant.
In the code block above, we begin by initializing the data loader using the DirectoryLoader class from langchain.document_loaders. We pass in the directory path where our text documents are stored as the first argument. In this example, the directory path is 'D:/OneDrive/Documents/Obsidian/Projects/myVault/'. Feel free to replace this with the path to your own text document directory.
The next parameter, glob, allows us to specify the file pattern or extension of the documents we want to load. In this case, we use "**/*.md" to load all Markdown files (*.md) in the directory and its subdirectories. You can modify this pattern to suit your specific file types or naming conventions.
Setting recursive=True ensures that the loader explores subdirectories within the specified directory, enabling us to load documents from a nested structure if necessary.
The show_progress parameter controls whether the loader displays a progress bar while loading the documents. Setting it to True provides visibility into the loading process, especially useful for larger knowledge bases.
To enhance performance, we can leverage multithreading by setting use_multithreading=True. This speeds up the loading process by loading multiple documents concurrently.
Finally, we specify the loader class as TextLoader, which instructs the data loader to treat each document as a text file.
After setting up the loader, we proceed to load the documents using the loader.load() method. This returns a list of document objects.
To verify the successful loading of documents, we print the length of the docs list using len(docs). This provides us with the count of loaded documents, ensuring that our data loader is functioning as expected.
Instantiate Embeddings and LLM
embeddings = HuggingFaceEmbeddings(model_name="all-mpnet-base-v2")
llm = GPT4All(model="./ggml-mpt-7b-instruct.bin", top_p=0.5, top_k=0, temp=0.5, repeat_penalty=1.1, n_threads=12, n_batch=16, n_ctx=2048)
In order to enhance the language understanding and generation capabilities of our personalized AI assistant, we need to instantiate embeddings and a language model (LLM). These components will enable our assistant to grasp the context of conversations and generate coherent and relevant responses.
In the code block provided, we create an instance of the HuggingFaceEmbeddings class from langchain.embeddings. This class allows us to leverage pre-trained word embeddings from the Hugging Face library, which are powerful tools for capturing the meaning and context of words in our language model. We specify the model_name parameter as "all-mpnet-base-v2", which corresponds to a specific pre-trained model from Hugging Face's model repository. You can explore other available models or choose one that best suits your requirements.
Next, we instantiate the language model using the GPT4All class from langchain.llms. We pass in the model parameter to specify the path to our pre-trained language model. In this example, the model is located at "./ggml-mpt-7b-instruct.bin". Please ensure that you provide the correct path to your own pre-trained model.
Additionally, we set several parameters to fine-tune the behavior of our language model. These parameters include:
top_p=0.5: This parameter determines the cumulative probability threshold for the model's sampling during text generation. A lower value results in more focused and deterministic responses.top_k=0: This parameter sets the number of highest probability tokens to consider during text generation. Setting it to 0 means all tokens are considered, allowing for more diverse responses.temp=0.5: Thetempparameter controls the temperature of the model's softmax distribution during sampling. Higher values (e.g., 1.0) result in more randomness and creativity in generated text.repeat_penalty=1.1: This parameter discourages the model from repeating the same phrases or patterns excessively. Increasing the value further reduces repetitive responses.n_threads=12andn_batch=16: These parameters determine the number of threads and batch size used for parallel processing during text generation. Adjusting these values can optimize the performance of our language model.
Feel free to play around with these values to get suitable results. Or you can just stick to these values.
Create Vector Database and Memory
index = VectorstoreIndexCreator(embedding=embeddings).from_loaders([loader])
retriever = index.vectorstore.as_retriever(search_kwargs=dict(k=2))
memory = VectorStoreRetrieverMemory(retriever=retriever)
To retrieve information efficiently, we create a vector database using VectorstoreIndexCreator from langchain.indexes. It leverages our pre-trained word embeddings to index the loaded documents effectively.
Using the from_loaders method, we generate the vector database from the loaded documents using our chosen embeddings.
Next, we create a retriever using the as_retriever method of the vector database. This allows us to search for relevant documents based on queries, providing the necessary information for context-aware responses.
Finally, we create a memory system using VectorStoreRetrieverMemory, which bridges the vector database and the language model. It enhances the assistant's ability to recall relevant information during conversations, ensuring accurate and contextually appropriate responses.
Create Prompt Template
MPT-7B Instruct model was trained on data formatted in the dolly-15k format like shown:
_DEFAULT_TEMPLATE = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
###Instruction: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Do not make up answers and provide only information that you have.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
{input}
### Response:
"""
To structure the prompts for our personalized AI assistant, we use a template chosen specifically for the MPT-7B Instruct model. This model was trained on data formatted in the dolly-15k format, which is known for its effectiveness in generating instructive responses.
The template includes an instruction section, where the AI is encouraged to provide detailed and context-specific information. It also emphasizes that the AI should admit when it doesn't know the answer.
The previous conversation's relevant pieces and any additional input provided are incorporated into the prompt template. These elements contribute to the AI's understanding of the conversation's context.
The response section of the template is left empty, allowing the AI to generate its response based on the given context and instructions.
Inference
PROMPT = PromptTemplate(
input_variables=[ "history", "input"], template=_DEFAULT_TEMPLATE
)
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
# We set a very low max_token_limit for the purposes of testing.
memory = memory,
verbose=True
)
with torch.inference_mode():
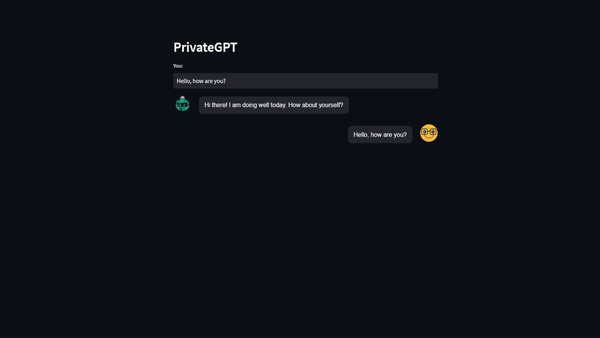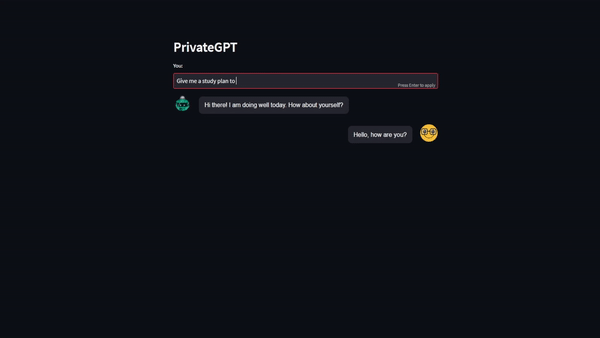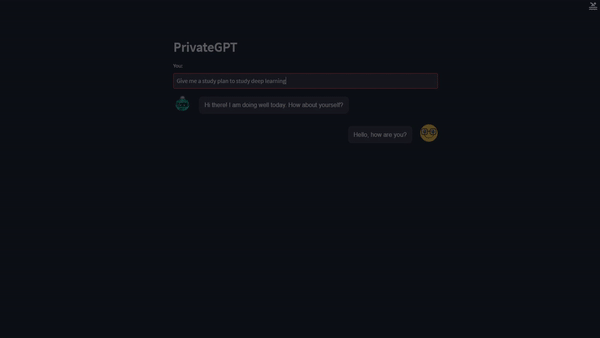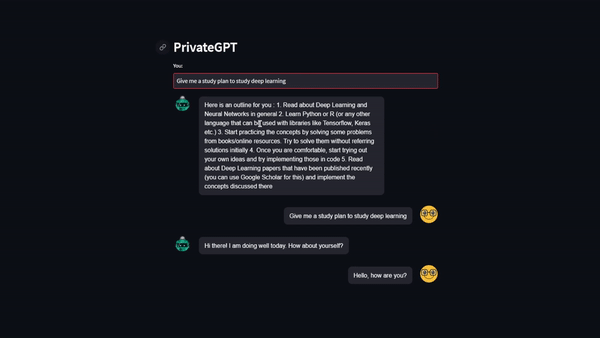
conversation_with_summary.predict(input = "Make me a study plan to study deep learning")
Now that we have set up our prompt template and created the necessary components for our personalized AI assistant, we can move on to the inference stage. In this stage, we utilize the conversation chain to generate responses based on the given input and context.
In the provided code block, we define a PROMPT object using the PromptTemplate class. This template incorporates the input variables history and input and the default template _DEFAULT_TEMPLATE we discussed earlier. It serves as the structure for our conversations, guiding the AI's responses.
Next, we create a ConversationChain object named conversation_with_summary. This chain utilizes our language model (llm), prompt template (PROMPT), and memory system (memory) to generate responses. We also set verbose=True to enable detailed output during the conversation.
Inside the with torch.inference_mode() block, we call the predict method of the conversation_with_summary object. We pass the input "give me more details" to initiate the conversation. The AI will utilize the prompt template, context from the conversation history, and the memory system to generate a relevant and informative response.
During this inference stage, the AI will leverage its knowledge and contextual understanding to generate responses that align with the conversation's flow and user's queries. The conversation chain ensures that the generated responses are coherent and contextually appropriate.
Create UI
st.set_page_config(
page_title="PrivateGPT",
page_icon=":robot:"
)
st.header("PrivateGPT")
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
def get_text():
input_text = st.text_input("You: ","Hello, how are you?", key="input")
return input_text
user_input = get_text()
def writeText(output):
st.session_state.generated.append(output)
if user_input:
with torch.inference_mode():
st.session_state.past.append(user_input)
st.session_state.generated.append(conversation_with_summary.predict(input = user_input))
if st.session_state['generated']:
for i in range(len(st.session_state['generated'])-1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
Run the App
streamlit run private_gpt.py
Want to connect?